传输链路
传输链路优化(Transmission Optimization)
今天的传输链路优化原则,在若干年后的未来再回头看它们时,其中多数已经成了奇技淫巧,有些甚至成了反模式 (opens new window)。
经过客户端缓存的节流、经过 DNS 服务的解析指引,程序发出的请求流量便正式离开客户端,踏上以服务器为目的地的旅途了,这个过程就是本节的主角:传输链路。
可能不少人的第一直觉会认为传输链路是开发者完全不可控的因素,网络路由跳点的数量、运营商铺设线路的质量决定了线路带宽的大小、速率的高低。然而事实并非如此,程序发出的请求能否与应用层、传输层协议提倡的方式相匹配,对传输的效率也会有极大影响。最容易体现这点的是那些前端网页的优化技巧,只要简单搜索一下,就能找到很多以优化链路传输为目的的前端设计原则,譬如经典的雅虎 YSlow-23 条规则 (opens new window)中与传输相关的内容如下。
- Minimize HTTP Requests。
减少请求数量:请求每次都需要建立通信链路进行数据传输,这些开销很昂贵,减少请求的数量可有效的提高访问性能,对于前端开发者,可能用来减少请求数量的手段包括:- 雪碧图(CSS Sprites (opens new window))
- CSS、JS 文件合并/内联(Concatenation / Inline)
- 分段文档(Multipart Document (opens new window))
- 媒体(图片、音频)内联(Data Base64 URI (opens new window))
- 合并 Ajax 请求(Batch Ajax Request)
- ……
- Split Components Across Domains。
扩大并发请求数:现代浏览器(Chrome、Firefox)一般对每个域名支持 6 个(IE 为 8-13 个)并发请求,如果希望更快地加载大量图片或其他资源,需要进行域名分片(Domain Sharding),将图片同步到不同主机或者同一个主机的不同域名上。 - GZip Components。
启用压缩传输:启用压缩能够大幅度减少需要在网络上传输内容的大小,节省网络流量。 - Avoid Redirects。
避免页面重定向:当页面发生了重定向,就会延迟整个文档的传输。在 HTML 文档到达之前,页面中不会呈现任何东西,降低了用户体验。 - Put Stylesheets at the Top,Put Scripts at the Bottom。
按重要性调节资源优先级:将重要的、马上就要使用的、对客户端展示影响大的资源,放在 HTML 的头部,以便优先下载。 - …………
这些原则在今天暂时仍算得上有一定价值,但在若干年后再回头看它们,大概率其中多数已经成了奇技淫巧,有些甚至成了反模式。导致这种变化的原因是 HTTP 协议还在持续发展,从 20 世纪 90 年代的 HTTP/1.0 和 HTTP/1.1,到 2015 年发布的 HTTP/2,再到 2019 年的 HTTP/3,由于 HTTP 协议本身的变化,使得“适合 HTTP 传输的请求”的特征也在不断变化。
连接数优化
我们知道 HTTP(特指 HTTP/3 以前)是以 TCP 为传输层的应用层协议,但 HTTP over TCP 这种搭配只能说是 TCP 在当今网络中统治性地位所造就的结果,而不能说它们两者配合工作就是合适的。回想一下你上网平均每个页面停留的时间,以及每个页面中包含的资源(HTML、JS、CSS、图片等)数量,可以总结出 HTTP 传输对象的主要特征是数量多、时间短、资源小、切换快。另一方面,TCP 协议要求必须在三次握手 (opens new window)完成之后才能开始数据传输,这是一个可能高达“百毫秒”为计时尺度的事件;另外,TCP 还有慢启动 (opens new window)的特性,使得刚刚建立连接时传输速度是最低的,后面再逐步加速直至稳定。由于 TCP 协议本身是面向于长时间、大数据传输来设计的,在长时间尺度下,它连接建立的高昂成本才不至于成为瓶颈,它的稳定性和可靠性的优势才能展现出来。因此,可以说 HTTP over TCP 这种搭配在目标特征上确实是有矛盾的,以至于 HTTP/1.x 时代,大量短而小的 TCP 连接导致了网络性能的瓶颈。为了缓解 HTTP 与 TCP 之间的矛盾,聪明的程序员们一面致力于减少发出的请求数量,另外一方面也致力于增加客户端到服务端的连接数量,这就是上面 Yslow 规则中“Minimize HTTP Requests”与“Split Components Across Domains”两条优化措施的根本依据所在。
通过前端开发者的各种 Tricks,的确能够减少消耗 TCP 连接数量,这是有数据统计作为支撑的。图 4-2 和图 4-3 展示了 HTTP Archive (opens new window)对最近五年来数百万个 URL 地址采样得出的结论:页面平均请求没有改变的情况下(桌面端下降 3.8%,移动端上升 1.4%),TCP 连接正在持续且幅度较大地下降(桌面端下降 36.4%,移动端下降 28.6%)。
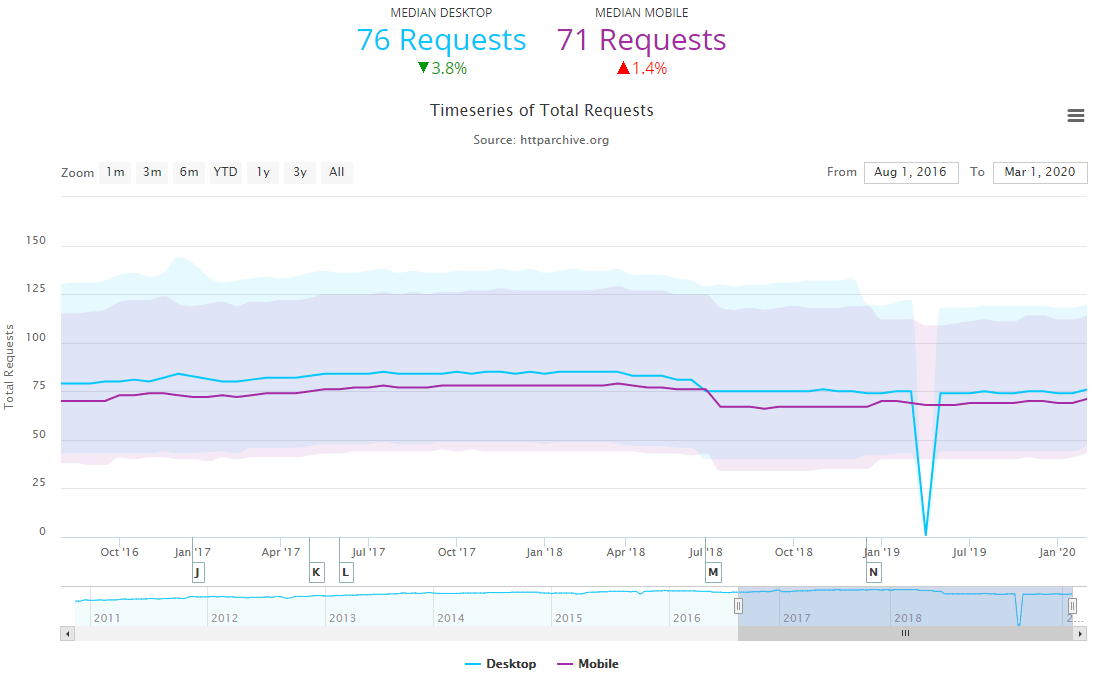 图 4-2 HTTP 平均请求数量,70 余个,没有明显变化
图 4-2 HTTP 平均请求数量,70 余个,没有明显变化
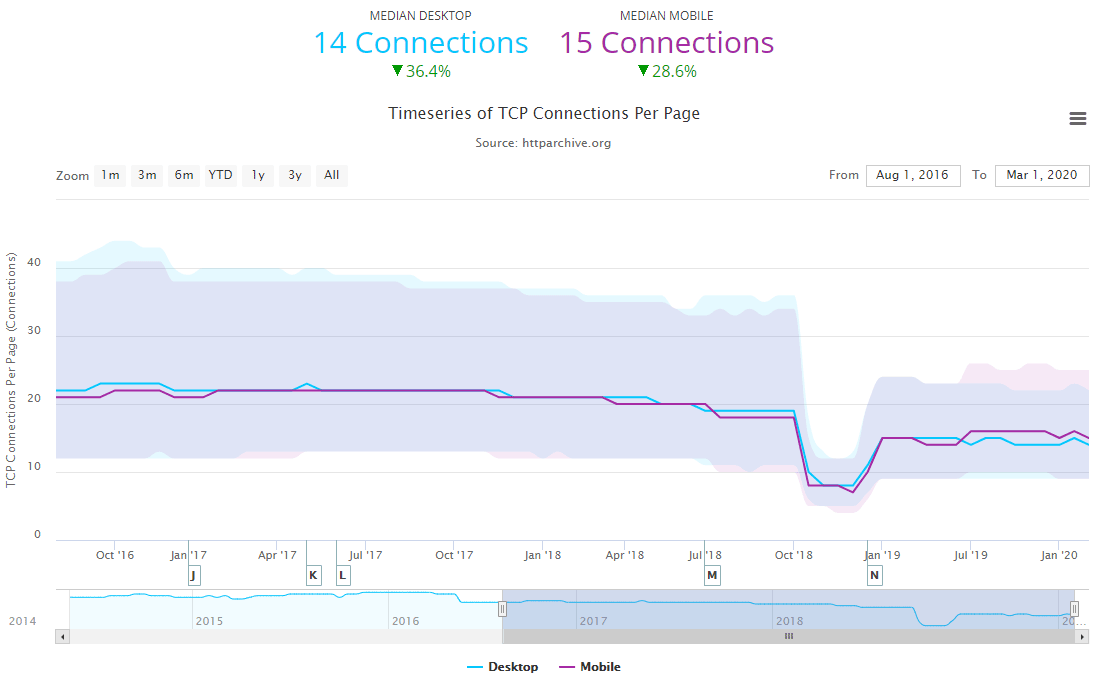 图 4-3 TCP 连接数量,约 15 个,有明显下降趋势
图 4-3 TCP 连接数量,约 15 个,有明显下降趋势
但是,通过开发人员的 Tricks 来节省 TCP 连接,这样的优化措施并非只有好处,它们同时也带来了诸多不良的副作用:
- 如果你用 CSS Sprites 将多张图片合并,意味着任何场景下哪怕只用到其中一张小图,也必须完整加载整个大图片;任何场景下哪怕一张小图要进行修改,都会导致整个缓存失效,类似地,样式、脚本等其他文件的合并也会造成同样的问题。
- 如果你使用了媒体内嵌,除了要承受 Base64 编码导致传输容量膨胀 1/3 的代价外(Base64 以 8 bit 表示 6 bit 数据),也将无法有效利用缓存。
- 如果你合并了异步请求,这就会导致所有请求返回时间都受最慢的那个请求的拖累,整体响应速度下降.
- 如果你把图片放到不同子域下面,将会导致更大的 DNS 解析负担,而且浏览器对两个不同子域下的同一图片必须持有两份缓存,也使得缓存效率的下降。
- ……
由此可见,一旦在技术根基上出现问题,依赖使用者通过各种 Tricks 去解决,无论如何都难以摆脱“两害相权取其轻”的权衡困境,否则这就不是 Tricks 而是会成为一种标准的设计模式了。
在另一方面,HTTP 的设计者们并不是没有尝试过在协议层面去解决连接成本过高的问题,即使是 HTTP 协议的最初版本(指 HTTP/1.0,忽略非正式的 HTTP/0.9 版本)就已经支持了连接复用技术(连接复用技术在 HTTP/1.0 中并不是默认开启的,是在 HTTP/1.1 中变为默认开启),即今天大家所熟知的持久连接 (opens new window)(Persistent Connection),也称为连接Keep-Alive 机制 (opens new window)。持久连接的原理是让客户端对同一个域名长期持有一个或多个不会用完即断的 TCP 连接。典型做法是在客户端维护一个 FIFO 队列,每次取完数据(如何在不断开连接下判断取完数据将会放到稍后传输压缩部分去讨论)之后一段时间内不自动断开连接,以便获取下一个资源时直接复用,避免创建 TCP 连接的成本。
但是,连接复用技术依然是不完美的,最明显的副作用是“队首阻塞 (opens new window)”(Head-of-Line Blocking)问题。请设想以下场景:浏览器有 10 个资源需要从服务器中获取,此时它将 10 个资源放入队列,入列顺序只能按照浏览器遇见这些资源的先后顺序来决定的。但如果这 10 个资源中的第 1 个就让服务器陷入长时间运算状态会怎样呢?当它的请求被发送到服务端之后,服务端开始计算,而运算结果出来之前 TCP 连接中并没有任何数据返回,此时后面 9 个资源都必须阻塞等待。因为服务端虽然可以并行处理另外 9 个请求(譬如第 1 个是复杂运算请求,消耗 CPU 资源,第 2 个是数据库访问,消耗数据库资源,第 3 个是访问某张图片,消耗磁盘 I/O 资源,这就很适合并行),但问题是处理结果无法及时返回客户端,服务端不能哪个请求先完成就返回哪个,更不可能将所有要返回的资源混杂到一起交叉传输,原因是只使用一个 TCP 连接来传输多个资源的话,如果顺序乱了,客户端就很难区分哪个数据包归属哪个资源了。
2014 年,IETF 发布的RFC 7230 (opens new window)中提出了名为“HTTP 管道”(HTTP Pipelining)复用技术,试图在 HTTP 服务器中也建立类似客户端的 FIFO 队列,让客户端一次将所有要请求的资源名单全部发给服务端,由服务端来安排返回顺序,管理传输队列。无论队列维护在服务端还是客户端,其实都无法完全避免队首阻塞的问题,但由于服务端能够较为准确地评估资源消耗情况,进而能够更紧凑地安排资源传输,保证队列中两项工作之间尽量减少空隙,甚至做到并行化传输,从而提升链路传输的效率。可是,由于 HTTP 管道需要多方共同支持,协调起来相当复杂,推广得并不算成功。
队首阻塞问题一直持续到第二代的 HTTP 协议,即 HTTP/2 发布后才算是被比较完美地解决。在 HTTP/1.x 中,HTTP 请求就是传输过程中最小粒度的信息单位了,所以如果将多个请求切碎,再混杂在一块传输,客户端势必难以分辨重组出有效信息。而在 HTTP/2 中,帧(Frame)才是最小粒度的信息单位,它可以用来描述各种数据,譬如请求的 Headers、Body,或者用来做控制标识,譬如打开流、关闭流。这里说的流(Stream)是一个逻辑上的数据通道概念,每个帧都附带一个流 ID 以标识这个帧属于哪个流。这样,在同一个 TCP 连接中传输的多个数据帧就可以根据流 ID 轻易区分出开来,在客户端毫不费力地将不同流中的数据重组出不同 HTTP 请求和响应报文来。这项设计是 HTTP/2 的最重要的技术特征一,被称为 HTTP/2 多路复用 (opens new window)(HTTP/2 Multiplexing)技术,如图 4-4 所示。
 图 4-4 HTTP/2 的多路复用(图片来源 (opens new window))
图 4-4 HTTP/2 的多路复用(图片来源 (opens new window))
有了多路复用的支持,HTTP/2 就可以对每个域名只维持一个 TCP 连接(One Connection Per Origin)来以任意顺序传输任意数量的资源,既减轻了服务器的连接压力,开发者也不用去考虑域名分片这种事情来突破浏览器对每个域名最多 6 个连接数限制了。而更重要的是,没有了 TCP 连接数的压力,就无须刻意压缩 HTTP 请求了,所有通过合并、内联文件(无论是图片、样式、脚本)以减少请求数的需求都不再成立,甚至反而是徒增副作用的反模式。
说这是反模式,也许还有一些前端开发者会不同意,认为 HTTP 请求少一些总是好的,减少请求数量,最起码还减少了传输中耗费的 Headers。必须先承认一个事实,在 HTTP 传输中 Headers 占传输成本的比重是相当的大,对于许多小资源,甚至可能出现 Headers 的容量比 Body 的还要大,以至于在 HTTP/2 中必须专门考虑如何进行 Header 压缩的问题。但是,以下几个因素决定了通过合并资源文件减少请求数,对节省 Headers 成本也并没有太大帮助:
- Header 的传输成本在 Ajax(尤其是只返回少量数据的请求)请求中可能是比重很大的开销,但在图片、样式、脚本这些静态资源的请求中,通常并不占主要。
- 在 HTTP/2 中 Header 压缩的原理是基于字典编码的信息复用,简而言之是同一个连接上产生的请求和响应越多,动态字典积累得越全,头部压缩效果也就越好。所以 HTTP/2 是单域名单连接的机制,合并资源和域名分片反而对性能提升不利。
- 与 HTTP/1.x 相反,HTTP/2 本身反而变得更适合传输小资源了,譬如传输 1000 张 10K 的小图,HTTP/2 要比 HTTP/1.x 快,但传输 10 张 1000K 的大图,则应该 HTTP/1.x 会更快。这一方面是 TCP 连接数量(相当于多点下载)的影响,更多的是由于 TCP 协议可靠传输机制 (opens new window)导致的,一个错误的 TCP 包会导致所有的流都必须等待这个包重传成功,这个问题就是 HTTP/3 要解决的目标了。因此,把小文件合并成大文件,在 HTTP/2 下是毫无好处的。
传输压缩
我们接下来再来讨论链路优化中缓存、连接之外另一个主要话题:压缩,同时也是为了解决上一节遗留的问题:如何不以断开 TCP 连接为标志来判断资源已传输完毕。
HTTP 很早就支持了GZip (opens new window)压缩,由于 HTTP 传输的主要内容,譬如 HTML、CSS、Script 等,主要是文本数据,对于文本数据启用压缩的收益是非常高的,传输数据量一般会降至原有的 20%左右。而对于那些不适合压缩的资源,Web 服务器则能根据 MIME 类型来自动判断是否对响应进行压缩,这样,已经采用过压缩算法存储的资源,如 JPEG、PNG 图片,便不会被二次压缩,空耗性能。
不过,大概就没有多少人想过压缩与之前提到的用于节约 TCP 的持久连接机制是存在冲突的。在网络时代的早期,服务器处理能力还很薄弱,为了启用压缩,会是把静态资源先预先压缩为.gz 文件的形式存放起来,当客户端可以接受压缩版本的资源时(请求的 Header 中包含 Accept-Encoding: gzip)就返回压缩后的版本(响应的 Header 中包含 Content-Encoding: gzip),否则就返回未压缩的原版,这种方式被称为“静态预压缩 (opens new window)”(Static Precompression)。而现代的 Web 服务器处理能力有了大幅提升,已经没有人再采用麻烦的预压缩方式了,都是由服务器对符合条件的请求将在输出时进行“即时压缩 (opens new window)”(On-The-Fly Compression),整个压缩过程全部在内存的数据流中完成,不必等资源压缩完成再返回响应,这样可以显著提高“首字节时间 (opens new window)”(Time To First Byte,TTFB),改善 Web 性能体验。而这个过程中唯一不好的地方就是服务器再也没有办法给出 Content-Length 这个响应 Header 了,因为输出 Header 时服务器还不知道压缩后资源的确切大小。
到这里,大家想明白即时压缩与持久链接的冲突在哪了吗?持久链接机制不再依靠 TCP 连接是否关闭来判断资源请求是否结束,它会重用同一个连接以便向同一个域名请求多个资源,这样,客户端就必须要有除了关闭连接之外的其他机制来判断一个资源什么时候算传递完毕,这个机制最初(在 HTTP/1.0 时)就只有 Content-Length,即靠着请求 Header 中明确给出资源的长度,传输到达该长度即宣告一个资源的传输已结束。由于启用即时压缩后就无法给出 Content-Length 了,如果是 HTTP/1.0 的话,持久链接和即时压缩只能二选其一,事实上在 HTTP/1.0 中两者都支持,却默认都是不启用的。依靠 Content-Length 来判断传输结束的缺陷,不仅仅在于即时压缩这一种场景,譬如对于动态内容(Ajax、PHP、JSP 等输出),服务器也同样无法事先得知 Content-Length。
HTTP/1.1 版本中修复了这个缺陷,增加了另一种“分块传输编码 (opens new window)”(Chunked Transfer Encoding)的资源结束判断机制,彻底解决了 Content-Length 与持久链接的冲突问题。分块编码原理相当简单:在响应 Header 中加入“Transfer-Encoding: chunked”之后,就代表这个响应报文将采用分块编码。此时,报文中的 Body 需要改为用一系列“分块”来传输。每个分块包含十六进制的长度值和对应长度的数据内容,长度值独占一行,数据从下一行开始。最后以一个长度值为 0 的分块来表示资源结束。举个具体例子(例子来自于维基百科 (opens new window),为便于观察,只分块,未压缩):
HTTP/1.1 200 OK
Date: Sat, 11 Apr 2020 04:44:00 GMT
Transfer-Encoding: chunked
Connection: keep-alive
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0
根据分块长度可知,前两个分块包含显式的回车换行符(CRLF,即\r\n 字符)
"This is the data in the first chunk\r\n" (37 字符 => 十六进制: 0x25)
"and this is the second one\r\n" (28 字符 => 十六进制: 0x1C)
"con" (3 字符 => 十六进制: 0x03)
"sequence" (8 字符 => 十六进制: 0x08)
所以解码后的内容为:
This is the data in the first chunk
and this is the second one
consequence
一般来说,Web 服务器给出的数据分块大小应该(但并不强制)是一致的,而不是如例子中那样随意。HTTP/1.1 通过分块传输解决了即时压缩与持久连接并存的问题,到了 HTTP/2,由于多路复用和单域名单连接的设计,已经无须再刻意去提持久链接机制了,但数据压缩仍然有节约传输带宽的重要价值。
快速 UDP 网络连接
HTTP 是应用层协议而不是传输层协议,它的设计原本并不应该过多地考虑底层的传输细节,从职责上讲,持久连接、多路复用、分块编码这些能力,已经或多或少超过了应用层的范畴。要从根本上改进 HTTP,必须直接替换掉 HTTP over TCP 的根基,即 TCP 传输协议,这便最新一代 HTTP/3 协议的设计重点。
推动替换 TCP 协议的先驱者并不是 IETF,而是 Google 公司。目前,世界上只有 Google 公司具有这样的能力,这并不是因为 Google 的技术实力雄厚,而是由于它同时持有着占浏览器市场 70%份额的 Chrome 浏览器与占移动领域半壁江山的 Android 操作系统。
2013 年,Google 在它的服务器(如 Google.com、YouTube.com 等)及 Chrome 浏览器上同时启用了名为“快速 UDP 网络连接 (opens new window)”(Quick UDP Internet Connections,QUIC)的全新传输协议。在 2015 年,Google 将 QUIC 提交给 IETF,并在 IETF 的推动下对 QUIC 进行重新规范化(为以示区别,业界习惯将此前的版本称为 gQUIC,规范化后的版本称为 iQUIC),使其不仅能满足 HTTP 传输协议,日后还能支持 SMTP、DNS、SSH、Telnet、NTP 等多种其他上层协议。2018 年末,IETF 正式批准了 HTTP over QUIC 使用 HTTP/3 的版本号,将其确立为最新一代的互联网标准。
从名字上就能看出 QUIC 会以 UDP 协议为基础,而 UDP 协议没有丢包自动重传的特性,因此 QUIC 的可靠传输能力并不是由底层协议提供,而是完全由自己来实现。由 QUIC 自己实现的好处是能对每个流能做单独的控制,如果在一个流中发生错误,协议栈仍然可以独立地继续为其他流提供服务。这对提高易出错链路的性能非常有用,因为在大多数情况下,TCP 协议接到数据包丢失或损坏通知之前,可能已经收到了大量的正确数据,但是在纠正错误之前,其他的正常请求都会等待甚至被重发,这也是在连接数优化一节中,笔者提到 HTTP/2 未能解决传输大文件慢的根本原因。
QUIC 的另一个设计目标是面向移动设备的专门支持,由于以前 TCP、UDP 传输协议在设计时根本不可能设想到今天移动设备盛行的场景,因此肯定不会有任何专门的支持。QUIC 在移动设备上的优势体现在网络切换时的响应速度上,譬如当移动设备在不同 WiFi 热点之间切换,或者从 WiFi 切换到移动网络时,如果使用 TCP 协议,现存的所有连接都必定会超时、中断,然后根据需要重新创建。这个过程会带来很高的延迟,因为超时和重新握手都需要大量时间。为此,QUIC 提出了连接标识符的概念,该标识符可以唯一地标识客户端与服务器之间的连接,而无须依靠 IP 地址。这样,切换网络后,只需向服务端发送一个包含此标识符的数据包即可重用既有的连接,因为即使用户的 IP 地址发生变化,原始连接连接标识符依然是有效的。
无论是 TCP 协议还是 HTTP 协议,都已经存在了数十年时间。它们积累了大量用户的同时,也承载了很重的技术惯性,要使 HTTP 从 TCP 迁移走,即使由 Google 和 IETF 来推动依然不是一件容易的事情。一个最显著的问题是互联网基础设施中的许多中间设备,都只面向 TCP 协议去建造,仅对 UDP 提供很基础的支持,有的甚至完全阻止 UDP 的流量。因此,Google 在 Chromium 的网络协议栈中同时启用了 QUIC 和传统 TCP 连接,并在 QUIC 连接失败时以零延迟回退到 TCP 连接,尽可能让用户无感知地逐步地扩大 QUIC 的使用面。
根据W3Techs (opens new window)的数据,截至 2020 年 10 月,全球已有 48.9%的网站支持了 HTTP/2 协议,按照维基百科中的记录,这个数字在 2019 年 6 月时还只是 36.5%。在 HTTP/3 方面,今天也已经得到了 7.2%网站的支持。可以肯定地说,目前网络链路传输领域正处于新旧交替的时代,许多既有的设备、程序、知识都会在未来几年时间里出现重大更新。