容器网络与生态
容器网络的第一个业界标准源于 Docker 在 2015 年发布的libnetwork (opens new window)项目,如果你还记得在“容器的崛起”中关于libcontainer (opens new window)的故事,那从名字上就很容易推断出 libnetwork 项目的目的与意义所在。这是 Docker 用 Golang 编写的、专门用来抽象容器间网络通信的一个独立模块,与 libcontainer 是作为 OCI 的标准实现类似,libnetwork 是作为 Docker 提出的 CNM 规范(Container Network Model)的标准实现而设计的。不过,与 libcontainer 因孵化出 runC 项目,时至今日仍然广为人知的结局不同,libnetwork 随着 Docker Swarm 的失败,已经基本失去了实用价值,只具备历史与学术研究方面的价值了。
CNM 与 CNI
如今容器网络的事实标准CNI (opens new window)(Container Networking Interface)与 CNM 在目标上几乎是完全重叠的,由此决定了 CNI 与 CNM 之间只能是你死我活的竞争关系,这与容器运行时中提及的 CRI 和 OCI 的关系明显不同,CRI 与 OCI 目标并不一样,两者有足够空间可以和平共处。
尽管 CNM 规范已是明日黄花,但它作为容器网络的先行者,对后续的容器网络标准制定有直接的指导意义,提出容器网络标准的目的就是为了把网络功能从容器运行时引擎或者容器编排系统中剥离出去,网络的专业性和针对性极强,如果不把它变成外部可扩展的功能,都由自己来做的话,不仅费时费力,还难以讨好。这个特点从图 12-9 所列的一大堆容器网络提供商就可见一斑。
 图 12-9 部分容器网络提供商
图 12-9 部分容器网络提供商
网络的专业性与针对性也决定了 CNM 和 CNI 均采用了插件式的设计,需要接入什么样的网络,就设计一个对应的网络插件即可。所谓的插件,在形式上也就是一个可执行文件,再配上相应的 Manifests 描述。为了方便插件编写,CNM 将协议栈、网络接口(对应于 veth、tap/tun 等)和网络(对应于 Bridge、VXLAN、MACVLAN 等)分别抽象为 Sandbox、Endpoint 和 Network,并在接口的 API 中提供了这些抽象资源的读写操作。而 CNI 中尽管也有 Sandbox、Network 的概念,含义也与 CNM 大致相同,不过在 Kubernetes 资源模型的支持下,它就无须刻意地强调某一种网络资源应该如何描述、如何访问了,因此结构上显得更加轻便。
从程序功能上看,CNM 和 CNI 的网络插件提供的能力都能划分为网络的管理与 IP 地址的管理两类,插件可以选择只实现其中的某一个,也可以全部都实现:
管理网络创建与删除。解决如何创建网络,如何将容器接入到网络,以及容器如何退出和删除网络。这个过程实际上是对容器网络的生命周期管理,如果你更熟悉 Docker 命令,可以类比理解为基本上等同于
docker network命令所做事情。CNM 规范中定义了创建网络、删除网络、容器接入网络、容器退出网络、查询网络信息、创建通信 Endpoint、删除通信 Endpoint 等十个编程接口,而 CNI 中就更加简单了,只要实现对网络的增加与删除两项操作即可。你甚至不需要学过 Golang 语言,只从名称上都能轻松看明白以下接口中每个方法的含义是什么:type CNI interface { AddNetworkList (net *NetworkConfigList, rt *RuntimeConf) (types.Result, error) DelNetworkList (net *NetworkConfigList, rt *RuntimeConf) error AddNetwork (net *NetworkConfig, rt *RuntimeConf) (types.Result, error) DelNetwork (net *NetworkConfig, rt *RuntimeConf) error }管理 IP 地址分配与回收。解决如何为三层网络分配唯一的 IP 地址的问题,二层网络的 MAC 地址天然就具有唯一性,无须刻意地考虑如何分配的问题。但是三层网络的 IP 地址只有通过精心规划,才能保证在全局网络中都是唯一的,否则,如果两个容器之间可能存在相同地址,那它们就最多只能做 NAT,而不可能做到直接通信。
相比起基于 UUID 或者数字序列实现的全局唯一 ID 产生器,IP 地址的全局分配工作要更加困难一些,首先是要符合 IPv4 的网段规则,且保证不重复,这在分布式环境里只能依赖 Etcd、ZooKeeper 等协调工具来实现,Docker 自己也提供了类似的 libkv 来完成这项工作。其次是必须考虑到回收的问题,否则一旦 Pod 发生持续重启就有可能耗尽某个网段中的所有地址。最后还必须要关注时效性,原本 IP 地址的获取采用标准的DHCP (opens new window)协议(Dynamic Host Configuration Protocol)即可,但 DHCP 有可能产生长达数秒的延迟,对于某些生存周期很短的 Pod,这已经超出了它的忍受限度,因此在容器网络中,往往 Host-Local 的 IP 分配方式会比 DHCP 更加实用。
CNM 到 CNI
容器网络标准能够提供一致的网络操作界面,不论是什么网络插件都使用一致的 API,提高了网络配置的自动化程度和在不同网络间迁移的体验,对最终用户、容器提供商、网络提供商来说都是三方共赢的事情。
CNM 规范发布以后,借助 Docker 在容器领域的强大号召力,很快就得到了网络提供商与开源组织的支持,不说专门为 Docker 设计针对容器互联的网络,最起码也会让现有的网络方案兼容于 CNM 规范,以便能在容器圈中多分一杯羹,譬如 Cisco 的Contiv (opens new window)、OpenStack 的Kuryr (opens new window)、Open vSwitch 的OVN (opens new window)(Open Virtual Networking)以及来自开源项目的Calico (opens new window)和Weave (opens new window)等都是 CNM 阵营中的成员。唯一对 CNM 持有不同意见的是那些和 Docker 存在直接竞争关系的产品,譬如 Docker 的最大竞争对手,来自 CoreOS 公司的RKT (opens new window)容器引擎。其实凭良心说,并不是其他容器引擎想刻意去抵制 CNM,而是 Docker 制定 CNM 规范时完全基于 Docker 本身来设计,并没有考虑 CNM 用于其他容器引擎的可能性。
为了平衡 CNM 规范的影响力,也是为了在 Docker 的垄断背景下寻找一条出路,RKT 提出了与 CNM 目标类似的“RKT 网络提案 (opens new window)”(RKT Networking Proposal)。一个业界标准成功与否,很大程度上取决于它支持者阵营的规模,对于容器网络这种插件式的规范更是如此。Docker 力推的 CNM 毫无疑问是当时统一容器网络标准的最有力竞争者,如果没有外力的介入,有极大可能会成为最后的胜利者。然而,影响容器网络发展的外力还是出现了,即使此前笔者没有提过 CNI,你也应该很容易猜到,在容器圈里能够掀翻 Docker 的“外力”,也就唯有 Kubernetes 一家而已。
Kubernetes 开源的初期(Kubernetes 1.5 提出 CRI 规范之前),在容器引擎上是选择彻底绑定于 Docker 的,但是,在容器网络的选择上,Kubernetes 一直都坚持独立于 Docker 自己来维护网络。CNM 和 CNI 提出以前的早期版本里,Kubernetes 会使用 Docker 的空置网络模式(--network=none)来创建 Pause 容器,然后通过内部的 kubenet 来创建网络设施,再让 Pod 中的其他容器加入到 Pause 容器的名称空间中共享这些网络设施。
额外知识:kubenet
kubenet (opens new window)是 kubelet 内置的一个非常简单的网络,采用网桥来解决 Pod 间通信。kubenet 会自动创建一个名为 cbr0 的网桥,当有新的 Pod 启动时,会由 kubenet 自动将其接入 cbr0 网桥中,再将控制权交还给 kubelet,完成后续的 Pod 创建流程。kubenet 采用 Host-Local 的 IP 地址管理方式,具体来说是根据当前服务器对应的 Node 资源上的PodCIDR字段所设的网段来分配 IP 地址。当有新的 Pod 启动时,会由本地节点的 IP 段中分配一个空闲的 IP 给 Pod 使用。
CNM 规范还未提出之前,Kubernetes 自己来维护网络是必然的结果,因为 Docker 自带的网络基本上只聚焦于如何解决本地通信,完全无法满足 Kubernetes 跨集群节点的容器编排的需要。CNM 规范提出之后,原本 Kubernetes 应该是除 Docker 外最大的受益者才对,CNM 的价值就是能很方便地引入其他网络插件来替代掉 Docker 自带的网络,但 Kubernetes 却对 Docker 的 CNM 规范表现得颇为犹豫,经过一番评估考量,Kubernetes 最终决定去转为支持当时极不成熟的 RKT 的网络提案,与 CoreOS 合作以 RKT 网络提案为基础发展出 CNI 规范。
Kubernetes Network SIG 的 Leader、Google 的工程师 Tim Hockin 专门撰写过一篇文章《Why Kubernetes doesn't use libnetwork (opens new window)》来解释为何 Kubernetes 要拒绝 CNM 与 libnetwork。当时容器编排战争还处于三国争霸(Kubernetes、Apache Mesos、Docker Swarm)的拉锯阶段,即使强势如 Kubernetes,拒绝 CNM 其实也要冒不小的风险,付出颇大的代价,因为这个决定不可避免会引发一系列技术和非技术的问题,譬如网络提供商要为 Kubernetes 专门编写不同的网络插件、由docker run启动的独立容器将会无法与 Kubernetes 启动的容器直接相互通信,等等。
促使 Kubernetes 拒绝 CNM 的理由也同样有来自于技术和非技术方面的。技术方面,Docker 的网络模型做出了许多对 Kubernetes 无效的假设:Docker 的网络有本地网络(不带任何跨节点协调能力,譬如 Bridge 模式就没有全局统一的 IP 分配)和全局网络(跨主机的容器通信,例如 Overlay 模式)的区别,本地网络对 Kubernetes 来说毫无意义,而全局网络又默认依赖 libkv 来实现全局 IP 地址管理等跨机器的协调工作。这里的 libkv 是 Docker 建立的 lib*家族中另一位成员,用来对标 Etcd、ZooKeeper 等分布式 K/V 存储,这对于已经拥有了 Etcd 的 Kubernetes 来说如同鸡肋。非技术方面,Kubernetes 决定放弃 CNM 的原因很大程度上还是由于他们与 Docker 在发展理念上的冲突,Kubernetes 当时已经开始推进 Docker 从必备依赖变为可选引擎的重构工作,而 Docker 则坚持 CNM 只能基于 Docker 来设计。Tim Hockin 在文章中举了一个例子:CNM 的网络驱动没有向外部暴露网络所连接容器的具体名称,只使用一个内部分配的 ID 来代替,这让外部(包括网络插件和容器编排系统)很难将网络连接的容器与自己管理的容器对应关联起来,当他们向 Docker 开发人员反馈这个问题时,问题被以“工作符合预期结果”(Working as Intended)为理由直接关闭掉,Tim Hockin 还专门列出了这些问题的详细清单,如libnetwork #139 (opens new window)、libnetwork #486 (opens new window)、libnetwork #514 (opens new window)、libnetwork #865 (opens new window)、docker #18864 (opens new window),这种设计被 Kubernetes 认为是人为地给非 Docker 的第三方容器引擎使用 CNM 设置障碍。整个沟通过程中,Docker 表现得也极为强硬,明确表示他们对偏离当前路线或委托控制的想法都不太欢迎。上面这些“非技术”的问题,即使没有 Docker 的支持,Kubernetes 自己也并非不能从“技术上”去解决,但 Docker 的理念令 Kubernetes 感到忧虑,因为 Kubernetes 在 Docker 之上扩展的很多功能,Kubernetes 却并不想这些功能永远绑定在 Docker 之上。
CNM 与 libnetwork 是 2015 年 5 月 1 日发布的,CNI 则是在 2015 年 7 月发布,两者正式诞生只相差不到两个月时间,这显然是竞争的需要而非单纯的巧合。五年之后的今天,这场容器网络的话语权之争已经尘埃落定,CNI 获得全面的胜利,除了 Kubernetes 和 RKT 外,Amazon ECS、RedHat OpenShift、Apache Mesos、Cloud Foundry 等容器编排圈子中除了 Docker 之外其他具有影响力的参与者都已宣布支持 CNI 规范,原本已经加入了 CNM 阵营的 Contiv、Calico、Weave 网络提供商也纷纷推出了自己的 CNI 插件。
网络插件生态
时至今日,支持 CNI 的网络插件已多达数十种,笔者不太可能逐一细说,不过,跨主机通信的网络实现方式来去也就下面这三种,我们不妨以网络实现模式为主线,每种模式介绍一个具有代表性的插件,以达到对网络插件生态窥斑见豹的效果。
- Overlay 模式:我们已经学习过 Overlay 网络,知道这是一种虚拟化的上层逻辑网络,好处在于它不受底层物理网络结构的约束,有更大的自由度,更好的易用性;坏处是由于额外的包头封装导致信息密度降低,额外的隧道封包解包会导致传输性能下降。
在虚拟化环境(例如 OpenStack)中的网络限制往往较多,譬如不允许机器之间直接进行二层通信,只能通过三层转发。在这类被限制网络的环境里,基本上就只能选择 Overlay 网络插件,常见的 Overlay 网络插件有 Flannel(VXLAN 模式)、Calico(IPIP 模式)、Weave 等等。
这里以 Flannel-VXLAN 为例,由 CoreOS 开发的 Flannel 可以说是最早的跨节点容器通信解决方案,很多其他网络插件的设计中都能找到 Flannel 的影子。早在 2014 年,VXLAN 还没有进入 Linux 内核的时候,Flannel 就已经开始流行,当时的 Flannel 只能采用自定义的 UDP 封包实现自己私有协议的 Overlay 网络,由于封包、解包的操作只能在用户态中进行,而数据包在内核态的协议栈中流转,这导致数据要反复在用户态、内核态之间拷贝,性能堪忧。从此 Flannel 就给人留下了速度慢的坏印象。VXLAN 进入 Linux 内核后,这种内核态用户态的转换消耗已经完全消失,Flannel-VXLAN 的效率比起 Flannel-UDP 有了很大提升,目前已经成为最常用的容器网络插件之一。 - 路由模式:路由模式其实属于 Underlay 模式的一种特例,这里将它单独作为一种网络实现模式来介绍。相比起 Overlay 网络,路由模式的主要区别在于它的跨主机通信是直接通过路由转发来实现的,因而无须在不同主机之间进行隧道封包。这种模式的好处是性能相比 Overlay 网络有明显提升,坏处是路由转发要依赖于底层网络环境的支持,并不是你想做就能做到的。路由网络要求要么所有主机都位于同一个子网之内,都是二层连通的,要么不同二层子网之间由支持边界网关协议 (opens new window)(Border Gateway Protocol,BGP)的路由相连,并且网络插件也同样支持 BGP 协议去修改路由表。
上一节介绍 Linux 网络基础知识时,笔者提到过 Linux 下不需要专门的虚拟路由,因为 Linux 本身就具备路由的功能。路由模式就是依赖 Linux 内置在系统之中的路由协议,将路由表分发到子网的每一台物理主机的。这样,当跨主机访问容器时,Linux 主机可以根据自己的路由表得知该容器具体位于哪台物理主机之中,从而直接将数据包转发过去,避免了 VXLAN 的封包解包而导致的性能降低。 常见的路由网络有 Flannel(HostGateway 模式)、Calico(BGP 模式)等等。
这里以 Flannel-HostGateway 为例,Flannel 通过在各个节点上运行的 Flannel Agent(Flanneld)将容器网络的路由信息设置到主机的路由表上,这样一来,所有的物理主机都拥有整个容器网络的路由数据,容器间的数据包可以被 Linux 主机直接转发,通信效率与裸机直连都相差无几,不过由于 Flannel Agent 只能修改它运行主机上的路由表,一旦主机之间隔了其他路由设备,譬如路由器或者三层交换机,这个包就会在路由设备上被丢掉,要解决这种问题就必须依靠 BGP 路由和 Calico-BGP 这类支持标准 BGP 协议修改路由表的网络插件共同协作才行。 - Underlay 模式:这里的 Underlay 模式特指让容器和宿主机处于同一网络,两者拥有相同的地位的网络方案。Underlay 网络要求容器的网络接口能够直接与底层网络进行通信,因此该模式是直接依赖于虚拟化设备与底层网络能力的。常见的 Underlay 网络插件有 MACVLAN、SR-IOV (opens new window)(Single Root I/O Virtualization)等。
对于真正的大型数据中心、大型系统,Underlay 模式才是最有发展潜力的网络模式。这种方案能够最大限度地利用硬件的能力,往往有着最优秀的性能表现。但也是由于它直接依赖于硬件与底层网络环境,必须根据软、硬件情况来进行部署,难以做到 Overlay 网络那样开箱即用的灵活性
这里以 SR-IOV 为例,SR-IOV 不是某种专门的网络名字,而是一种将PCIe (opens new window)设备共享给虚拟机使用的硬件虚拟化标准,目前用在网络设备上应用比较多,理论上也可以支持其他的 PCIe 硬件。通过 SR-IOV 能够让硬件在虚拟机上实现独立的内存地址、中断和 DMA 流,而无须虚拟机管理系统的介入。对于容器系统来说,SR-IOV 的价值是可以直接在硬件层面虚拟多张网卡,并且以硬件直通(Passthrough)的形式交付给容器使用。但是 SR-IOV 直通部署起来通常都较为繁琐,现在容器用的 SR-IOV 方案不少是使用MACVTAP (opens new window)来对 SR-IOV 网卡进行转接的,MACVTAP 提升了 SR-IOV 的易用性,但是这种转接又会带来额外的性能损失,并不一定会比其他网络方案有更好的表现。
了解过 CNI 插件的大致的实现原理与分类后,相信你的下一个问题就是哪种 CNI 网络最好?如何选择合适的 CNI 插件?选择 CNI 网络插件主要有两方面的考量因素,首先必须是你系统所处的环境是支持的,这点在前面已经有针对性地介绍过。在环境可以支持的前提下,另外一个因素就是性能与功能方面是否合乎你的要求。
性能方面,笔者引用一组测试数据供你参考。这些数据来自于 2020 年 8 月刊登在 IETF 的论文《Considerations for Benchmarking Network Performance in Containerized Infrastructures (opens new window)》,此文中测试了不同 CNI 插件在裸金属服务器 (opens new window)之间(BMP to BMP,Bare Metal Pod)、虚拟机之间(VMP to VMP,Virtual Machine Pod)、以及裸金属服务器与虚拟机之间(BMP to VMP)的本地网络和跨主机网络的通信表现。囿于篇幅,这里只列出最具代表性的是裸金属服务器之间的跨主机通信,其结果如图 12-10 与图 12-11 所示:
 图 12-10 512 Bytes - 1M Bytes 中 TCP 吞吐量(结果越高,性能越好)
图 12-10 512 Bytes - 1M Bytes 中 TCP 吞吐量(结果越高,性能越好)
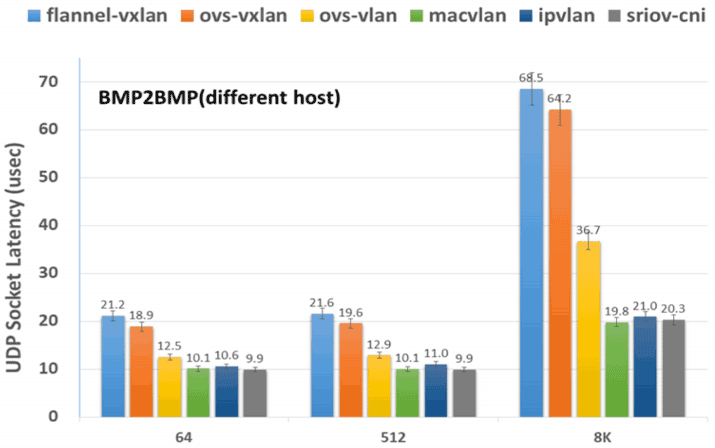 图 12-11 64 Bytes - 8K Bytes 中 UDP 延迟时间(结果越低,性能越好)
图 12-11 64 Bytes - 8K Bytes 中 UDP 延迟时间(结果越低,性能越好)
从测试结果可见,MACVLAN 和 SR-IOV 这样的 Underlay 网络插件的吞吐量最高、延迟最低,仅从网络性能上看它们肯定是最优秀的,相对而言 Flannel-VXLAN 这样的 Overlay 网络插件,其吞吐量只有 MACVLAN 和 SR-IOV 的 70%左右,延迟更是高了两至三倍之多。Overlay 为了易用性、灵活性所付出的代价还是不可忽视的,但是对于那些不以网络 I/O 为性能瓶颈的系统而言,这样的代价并非一定不可接受,就看你心中对通用性与性能是如何权衡取舍。
功能方面的问题就比较简单了,完全取决于你的需求是否能够满足。对于容器编排系统来说,网络并非孤立的功能模块,只提供网络通信就可以的,譬如 Kubernetes 的 NetworkPolicy 资源是用于描述“两个 Pod 之间是否可以访问”这类 ACL 策略。但它不属于 CNI 的范畴,因此不是每个 CNI 插件都会支持 NetworkPolicy 的声明,如果有这方面的需求,就应该放弃 Flannel,去选择 Calico、Weave 等插件。类似的其他功能上的选择的例子还有很多,笔者不再一一列举。
← Linux 网络虚拟化 持久化存储 →