使用 Kubeadm 部署
尽管使用 Rancher 或者 KubeSphere 这样更高层次的管理工具,可以更“傻瓜式”地部署和管理 Kubernetes 集群,但 kubeadm 作为官方提供的用于快速安装 Kubernetes 的命令行工具,仍然是一项应该掌握的基础技能。kubeadm 随着新版的 Kubernetes 同步更新,时效性也会比其他更高层次的管理工具来的更好。现在 kubeadm 无论是部署单控制平面(Single Control Plane,单 Master 节点)集群还是高可用(High Availability,多 Master 节点)集群,都已经有了很优秀的易用性,手工部署 Kubernetes 集群已经不是什么太复杂、困难的事情了。本文以 Debian 系的 Linux 为例,介绍通过 kubeadm 部署集群的全过程。
注意事项
- 安装 Kubernetes 集群,需要从谷歌的仓库中拉取镜像,由于国内访问谷歌的网络受阻,需要通过科学上网或者在 Docker 中预先拉取好所需镜像等方式解决。
- 集群中每台机器的 Hostname 不要重复,否则 Kubernetes 从不同机器收集状态信息时会产生干扰,被认为是同一台机器。
- 安装 Kubernetes 最小需要 2 核处理器、2 GB 内存,且为 x86 架构(暂不支持 ARM 架构)。对于物理机器来说,今时今日要找一台不满足以上条件的机器很困难,但对于云主机来说,尤其是囊中羞涩、只购买了云计算厂商中最低配置的同学,就要注意一下是否达到了最低要求,不清楚的话请在
/proc/cpuinf、/proc/meminfo中确认一下。 - 确保网络通畅的——这听起来像是废话,但确实有相当一部分的云主机不对 SELinux、iptables、安全组、防火墙进行设置的话,内网各个节点之间、与外网之间会存在默认的访问障碍,导致部署失败。 :::
注册 apt 软件源
由于 Kubernetes 并不在主流 Debian 系统自带的软件源中,所以要手工注册,然后才能使用apt-get安装。
官方的 GPG Key 地址为:https://packages.cloud.google.com/apt/doc/apt-key.gpg (opens new window),其中包括的软件源的地址为:https://apt.kubernetes.io/ (opens new window)(该地址最终又会被重定向至:https://packages.cloud.google.com/apt/ (opens new window))。如果能访问 google.com 域名的机器,采用以下方法注册 apt 软件源是最佳的方式:
# 添加GPG Key
$ sudo curl -fsSL https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
# 添加K8S软件源
$ sudo add-apt-repository "deb https://apt.kubernetes.io/ kubernetes-xenial main"
对于不能访问 google.com 的机器,就要借助国内的镜像源来安装了。虽然在这些镜像源中我已遇到过不止一次同步不及时的问题了——就是官方源中已经发布了软件的更新版本,而镜像源中还是旧版的,除了时效性问题外,还出现过其他的一些一致性问题,但是总归比没有的强。国内常见用的 apt 源有阿里云的、中科大的等,具体为:
阿里云:
- GPG Key:http://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg (opens new window)
- 软件源:http://mirrors.aliyun.com/kubernetes/apt (opens new window)
中科大:
它们的使用方式与官方源注册过程是一样的,只需替换里面的 GPG Key 和软件源的 URL 地址即可,譬如阿里云:
# 添加GPG Key
$ curl -fsSL http://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
# 添加K8S软件源
$ sudo add-apt-repository "deb http://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main"
添加源后记得执行一次更新:
$ sudo apt-get update
安装 kubelet、kubectl、kubeadm
并不需要在每个节点都装上 kubectl,但都装上也无不可。下面简要列出了这三个工具/组件的作用,现在看不看得懂都没有关系,以后用到它们的机会多得是,要相信日久总会生情的。
- kubeadm: 引导启动 Kubernate 集群的命令行工具。
- kubelet: 在群集中的所有计算机上运行的组件, 并用来执行如启动 Pods 和 Containers 等操作。
- kubectl: 用于操作运行中的集群的命令行工具。
$ sudo apt-get install kubelet kubeadm kubectl
初始化集群前的准备
在使用 kubeadm 初始化集群之前,还有一些必须的前置工作要妥善处理:
首先,基于安全性(如在官方文档中承诺的 Secret 只会在内存中读写,不会落盘)、利于保证节点同步一致性等原因,从 1.8 版开始,Kubernetes 就在它的文档中明确声明了它默认不支持Swap 分区,在未关闭 Swap 分区的机器中,集群将直接无法启动。关闭 Swap 的命令为:
$ sudo swapoff -a
上面这个命令是一次性的,只在当前这次启动中生效,要彻底关闭 Swap 分区,需要在文件系统分区表的配置文件中去直接除掉 Swap 分区。你可以使用文本编辑器打开/etc/fstab,注释其中带有“swap”的行即可,或使用以下命令直接完成修改:
# 还是先备份一下
$ yes | sudo cp /etc/fstab /etc/fstab_bak
# 进行修改
$ sudo cat /etc/fstab_bak | grep -v swap > /etc/fstab
可选操作
当然,在服务器上使用的话,关闭 Swap 影响还是很大的,如果服务器除了 Kubernetes 还有其他用途的话(除非实在太穷,否则建议不要这样混用;一定要混用的话,宁可把其他服务搬到 Kubernetes 上)。关闭 Swap 有可能会对其他服务产生不良的影响,这时需要修改每个节点的 kubelet 配置,去掉必须关闭 Swap 的默认限制,具体操作为:
$ echo "KUBELET_EXTRA_ARGS=--fail-swap-on=false" >> /etc/sysconfig/kubelet
其次,由于 Kubernetes 与 Docker 默认的 cgroup(资源控制组)驱动程序并不一致,Kubernetes 默认为systemd,而 Docker 默认为cgroupfs。
在这里我们要修改 Docker 或者 Kubernetes 其中一个的 cgroup 驱动,以便两者统一。根据官方文档《CRI installation (opens new window)》中的建议,对于使用 systemd 作为引导系统的 Linux 的发行版,使用 systemd 作为 Docker 的 cgroup 驱动程序可以服务器节点在资源紧张的情况表现得更为稳定。
这里选择修改各个节点上 Docker 的 cgroup 驱动为systemd,具体操作为编辑(无则新增)/etc/docker/daemon.json文件,加入以下内容即可:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
然后重新启动 Docker 容器:
$ systemctl daemon-reload
$ systemctl restart docker
预拉取镜像 可选
预拉取镜像并不是必须的,本来初始化集群的时候系统就会自动拉取 Kubernetes 中要使用到的 Docker 镜像组件,也提供了一个kubeadm config images pull命令来一次性的完成拉取,这都是因为如果要手工来进行这项工作,实在非常非常非常地繁琐。
但对于许多人来说这项工作往往又是无可奈何的,Kubernetes 的镜像都存储在 k8s.gcr.io 上,如果您的机器无法直接或通过代理访问到 gcr.io(Google Container Registry。笔者敲黑板:这也是属于谷歌的网址)的话,初始化集群时自动拉取就无法顺利进行,所以就不得不手工预拉取。
预拉取的意思是,由于 Docker 只要查询到本地有相同(名称和 tag 完全相同、哈希相同)的镜像,就不会访问远程仓库,那只要从 GitHub 上拉取到所需的镜像,再将 tag 修改成官方的一致,就可以跳过网络访问阶段。
首先使用以下命令查询当前版本需要哪些镜像:
$ kubeadm config images list --kubernetes-version v1.17.3
k8s.gcr.io/kube-apiserver:v1.17.3
k8s.gcr.io/kube-controller-manager:v1.17.3
k8s.gcr.io/kube-scheduler:v1.17.3
k8s.gcr.io/kube-proxy:v1.17.3
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.5
……
这里必须使用--kubernetes-version参数指定具体版本,因为尽管每个版本需要的镜像信息在本地是有存储的,但如果不加的话,Kubernetes 将向远程 GCR 仓库查询最新的版本号,会因网络无法访问而导致问题。但加版本号的时候切记不能照抄上面的命令中的“v1.17.3”,应该与你安装的 kubelet 版本保持一致,否则在初始化集群控制平面的时候会提示控制平面版本与 kubectl 版本不符。
得到这些镜像名称和 tag 后,可以从DockerHub (opens new window)上找存有相同镜像的仓库来拉取,至于具体哪些公开仓库有,考虑到以后阅读本文时 Kubernetes 的版本应该会有所差别,所以需要自行到DockerHub网站上查询一下。
#以k8s.gcr.io/coredns:1.6.5为例,每个镜像都要这样处理一次
$ docker pull anjia0532/google-containers.coredns:1.6.5
#修改tag
$ docker tag anjia0532/google-containers.coredns:1.6.5 k8s.gcr.io/coredns:1.6.5
#修改完tag后就可以删除掉旧镜像了
$ docker rmi anjia0532/google-containers.coredns:1.6.5
初始化集群控制平面
到了这里,终于可以开始 Master 节点的部署了,先确保 kubelet 是开机启动的:
$ sudo systemctl start kubelet
$ sudo systemctl enable kubelet
接下来使用 su 直接切换到 root 用户(而不是使用 sudo),然后使用以下命令开始部署:
$ kubeadm init \
--pod-network-cidr=10.244.0.0/16 \
--kubernetes-version v1.17.3 \
--apiserver-advertise-address <NET_INTERFACE_IP>
这里解释一下使用这几个参数的原因:
--kubernetes-version参数(要注意版本号与 kubelet 一致)的目的是与前面预拉取是一样的,避免额外的网络访问去查询版本号;如果能够科学上网,不需要加这个参数。
--pod-network-cidr参数是给Flannel网络做网段划分使用的,着在稍后介绍完 CNI 网络插件时会去说明。
--apiserver-advertise-address参数是APIServer的IP地址,如果有多张物理网卡,建议指定明确的IP地址来建立Kubernetes集群。因为CA证书直接与地址相关,Kubernetes中诸多配置(配置文件、ConfigMap资源)也直接存储了这个地址,一旦更换IP,要想要不重置集群,手工换起来异常麻烦。
命令执行完毕,当看到下面信息之后,说明集群主节点已经安装完毕了。
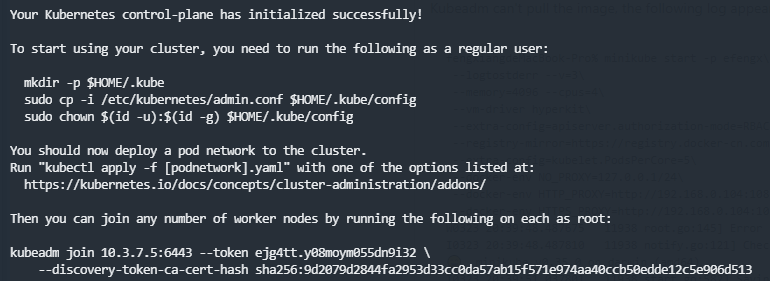
这信息先恭喜你已经把控制平面安装成功了,但还有三行“you need……”、“you should……”、“you can……”开头的内容,这是三项后续的“可选”工作,下面继续介绍。
为当前用户生成 kubeconfig
使用 Kubernetes 前需要为当前用户先配置好 admin.conf 文件。切换至需配置的用户后,进行如下操作:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
安装 CNI 插件 可选
CNI 即“容器网络接口”,在 2016 年,CoreOS 发布了 CNI 规范。2017 年 5 月,CNI 被 CNCF 技术监督委员会投票决定接受为托管项目,从此成为不同容器编排工具(Kubernetes、Mesos、OpenShift)可以共同使用的、解决容器之间网络通讯的统一接口规范。
部署 Kubernetes 时,我们可以有两种网络方案使得以后受管理的容器之间进行网络通讯:
- 使用 Kubernetes 的默认网络
- 使用 CNI 及其插件
第一种方案,尤其不在 GCP 或者 AWS 的云主机上,没有它们的命令行管理工具时,需要大量的手工配置,基本上是反人类的。实际通常都会采用第二种方案,使用 CNI 插件来处理容器之间的网络通讯,所以本节虽然标识了“可选”,但其实也并没什么选择不安装 CNI 插件的余地。
Kubernetes 目前支持的 CNI 插件有:Calico、Cilium、Contiv-VPP、Flannel、Kube-router、Weave Net 等多种,每种网络提供了不同的管理特性(如 MTU 自动检测)、安全特性(如是否支持网络层次的安全通讯)、网络策略(如 Ingress、Egress 规则)、传输性能(甚至对 TCP、UDP、HTTP、FTP、SCP 等不同协议来说也有不同的性能表现)以及主机的性能消耗。如果你还需要阅读本文来部署 Kubernetes 环境的话,那不用纠结了,直接使用 Flannel 是较为合适的,它是最精简的 CNI 插件之一,没有安全特性的支持,主机压力小,安装便捷,效率也不错,使用以下命令安装 Flannel 网络:
$ curl --insecure -sfL https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml | kubectl apply -f -
使用 Flannel 的话,要注意要在创建集群时加入--pod-network-cidr参数,指明网段划分。如果你是跟着本文去部署的话,这个操作之前已经包含了。
移除 Master 节点上的污点 可选
污点(Taint)是 Kubernetes Pod 调度中的概念,在这里通俗地理解就是 Kubernetes 决定在集群中的哪一个节点建立新的容器时,要先排除掉带有特定污点的节点,以避免容器在 Kubernetes 不希望运行的节点中创建、运行。默认情况下,集群的 Master 节点是会带有特定污点的,以避免容器分配到 Master 中创建。但对于许多学习 Kubernetes 的同学来说,并没有多么宽裕的机器数量,往往是建立单节点集群或者最多只有两、三个节点,这样 Master 节点不能运行容器就显得十分浪费了。如需移除掉 Master 节点上所有的污点,在 Master 节点上执行以下命令即可:
$ kubectl taint nodes --all node-role.kubernetes.io/master-
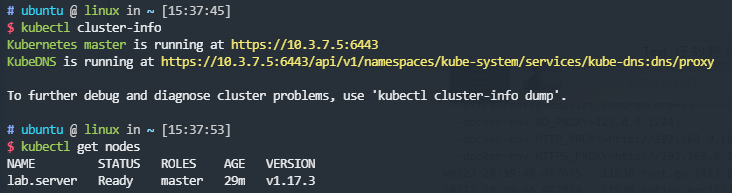
做到这步,如果你只有一台机器的话,那 Kubernetes 的安装已经宣告结束了,可以使用此环境来完成后续所有的部署。你还可以通过cluster-info和get nodes子命令来查看一下集群的状态,类似如下所示:
调整 NodePort 范围 可选
Kubernetes 默认的 NodePort 范围为 30000-32767,如果你是在测试环境,集群前端没有专门布置负载均衡器的话,那就经常需要通过 NodePort 来访问服务,这样限制了只能使用 30000 以上的端口,虽然能避免冲突,但并不够方便。为了方便使用低端口,可能需要修改此范围,这需要调整 Api-Server 的启动参数,具体操作如下(如过是高可用部署,需要对每一个 Master 节点进行修改):
修改
/etc/kubernetes/manifests/kube-apiserver.yaml文件,添加一个参数在spec.containers.command中增加一个参数--service-node-port-range=1-32767重启 Api-Server,现在 Kubernetes 基本都是以静态 Pods 模式部署,Api-Server 是一个直接由 kubelet 控制的静态 Pod,删除后它会自动重启:
# 获得 apiserver 的 pod 名字 export apiserver_pods=$(kubectl get pods --selector=component=kube-apiserver -n kube-system --output=jsonpath={.items..metadata.name}) # 删除 apiserver 的 pod kubectl delete pod $apiserver_pods -n kube-system验证修改结果:可以在 pod 中看到该参数即可
kubectl describe pod $apiserver_pods -n kube-system
启用 kubectl 命令自动补全功能 可选
由于 kubectl 命令在后面十分常用,而且 Kubernetes 许多资源名称都带有随机字符,要手工照着敲很容易出错,强烈推荐启用命令自动补全的功能,这里仅以 bash 和笔者常用的 zsh 为例,如果您使用其他 shell,需自行调整:
bash:
$ echo 'source <(kubectl completion bash)' >> ~/.bashrc $ echo 'source /usr/share/bash-completion/bash_completion' >> ~/.bashrczsh:
$ echo 'source <(kubectl completion zsh)' >> !/.zshrc
将其他 Node 节点加入到 Kubernetes 集群中
在安装 Master 节点时候,输出的最后一部分内容会类似如下所示:
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.3.7.5:6443 --token ejg4tt.y08moym055dn9i32 \
--discovery-token-ca-cert-hash sha256:9d2079d2844fa2953d33cc0da57ab15f571e974aa40ccb50edde12c5e906d513
这部分内容是告诉用户,集群的 Master 节点已经建立完毕,其他节点的机器可以使用“kubeadm join”命令加入集群。这些机器只要完成 kubeadm、kubelet、kubectl 的安装即可、其他的所有步骤,如拉取镜像、初始化集群等,都不需要去做,就是可以使用该命令加入集群了。需要注意的是,该 Token 的有效时间为 24 小时,如果超时,使用以下命令重新获取:
$ kubeadm token create --print-join-command